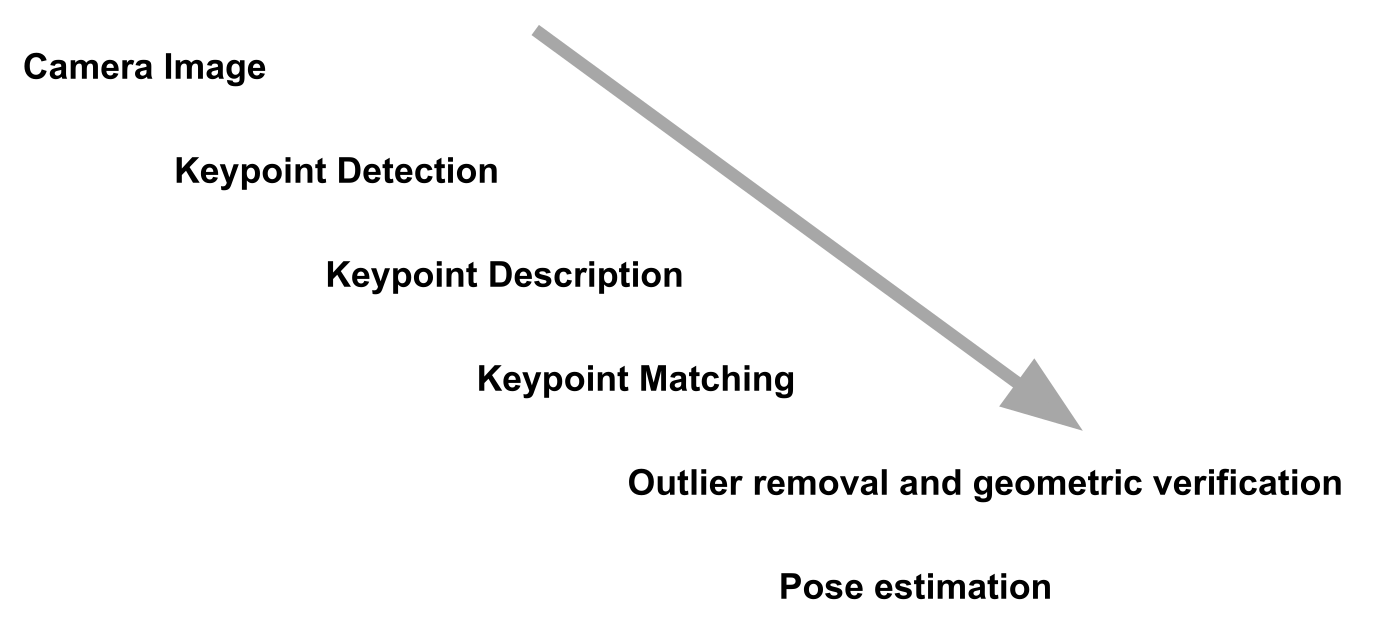
Markerless
Marker vs Markerless Tracking

Scale Invariant Feature Transform (SIFT)

To do markerless tracking, one needs a template in advance (in this example the basmati rice). The algorithm then finds points of interest.
Interests points should be of quality, stable and robust with respect to perspective distortions, illuminations, etc. Additionally, since there are a lot of points, if part of the template is occluded, the algorithm can still resolve its position in an image, since there are still enough points of interest.
These points of interest are then found in the image and matched.
For SIFT to work well, the template needs to be distinctive

Feature Detection
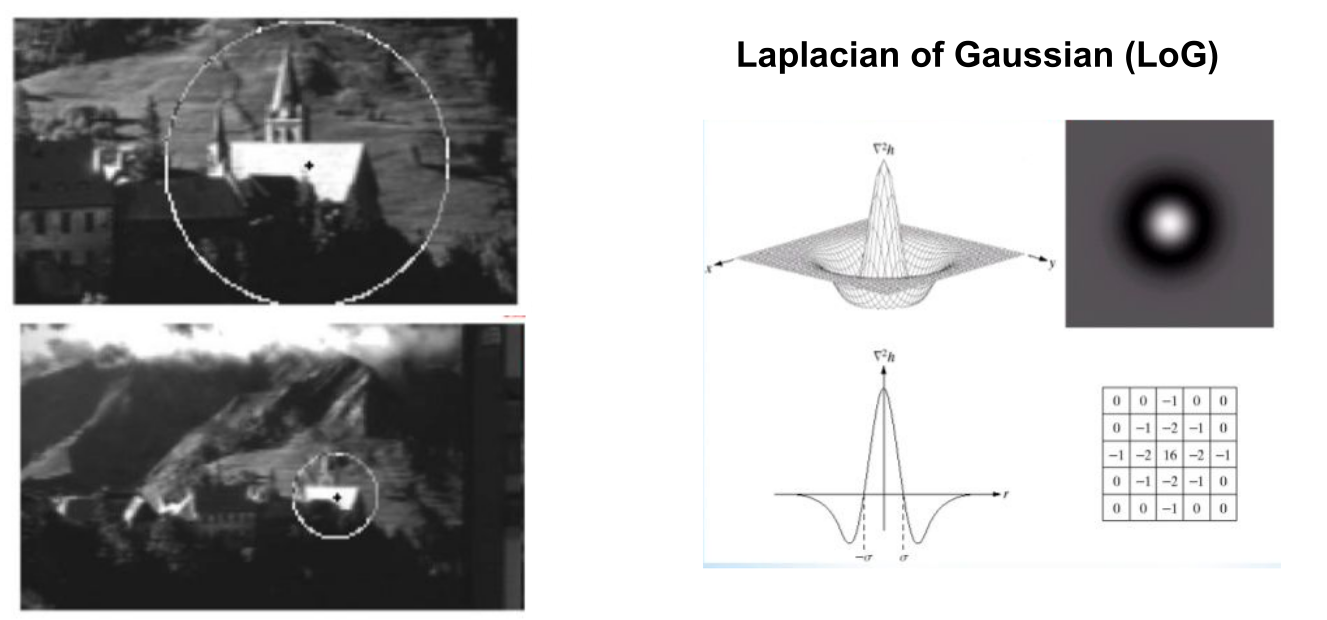
To find points, a laplacian of gaussian kernel can be slided over the image and record where it fits. This finds bright spots, surrounded by a dark surrounding. There are multiple ways, how to do this quickly.
Because of this, SIFT is scale invariant, as the scale can change and the filter will still find the same spots.
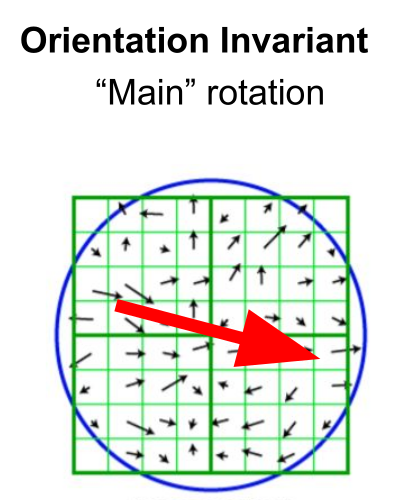
To find the rotation, every vector is summed together and find overall main rotation. The vector field avoid is not temporal, rather it is how the grayscale image changes from left to right, and top to bottom.
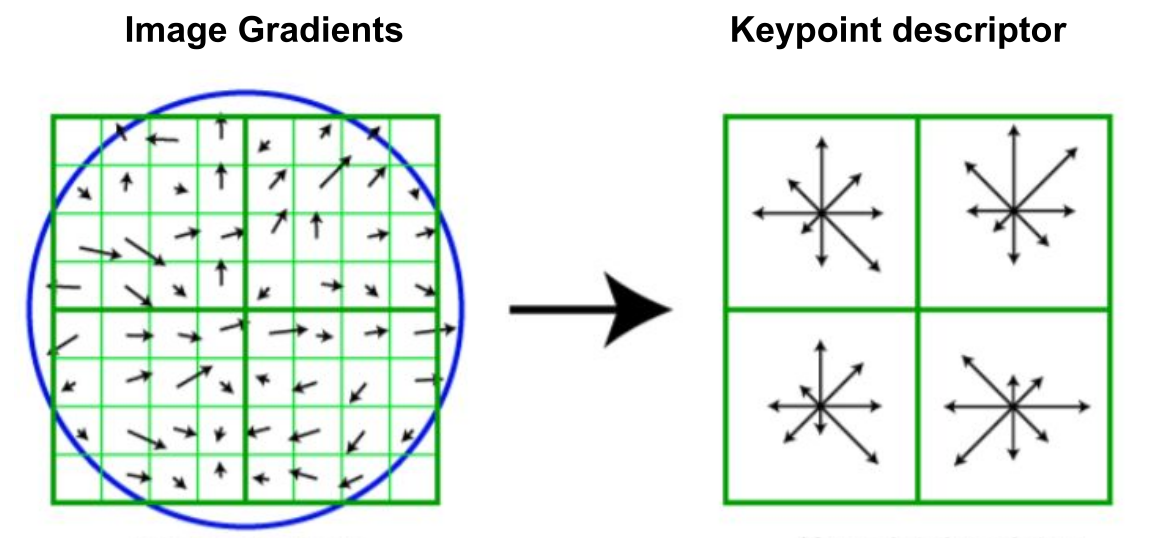
The position can be described by splitting the gradient in four quadrants and binning each quadrant with 8 bins. This gives us 128 dim descriptors, that describe the position.
Feature Matching
Feature matching is finding a point of interest of the template in the image. For this, the algorithm needs to find the closest matching 128 dim descriptor from above.
An algorithm needs to find the nearest neighbour in the the descriptor space (not the image space).
To reduce noise, the ratio between the first nearest neighbour and the second nearest neighbour needs to be big enough.
Feature matching is made difficult by the shear amount of outliers. This can be reduced by Random Sampling Consensus (RANSAC). In the example below, a line is used as a model. However, for feature matching a plane is used. More concretely, the equations (homography) from Intro can as a model.
Random Sampling Consensus (RANSAC)
The input are:
- a set of data points \(U\)
- a function which computes the models parameters given some sample \(S \sub U\)
- a cost function for a single point in \(U\)

In the third step, the algorithm checks how accurate the thesis created by (2) is.
This is done multiple times, and the model with the most inliers is chosen.
a)
- Zuerst muss Feature Detection (e.g. mit SIFT) auf den einzelnen Bildern durch geführt werden
- Danach muss die Essential-Matrix und Fundamental-Matrix errechnet werden. Damit kann die Kamera Position und Rotation berechnet werden
- Wenn die Position und Rotatioon der Cameras bekannt ist, kann nun die Tiefe der Punkte berechnet werden und eine Punkte Wolke daraus erechnet werden.
- Bundle Adjust ist der Schritt, in welchem weitere Bilder benützt werden, um die Punktewolke zu verbesseren
- Nun kann eine Dense Point Cloud erechnet werdne
- Mit dieser kann im letzten Schritt die Flächen wieder hergestellt werden
b)
Um die Essential-Matrix zu bekommen muss zuerst die Fundamental-Matrix geschtätz werden. Dafür wird meistens der RANSAC algorithmus verwendet. Es gibt auch die 8-Point methode, allerdings, da die Features automatisch aus zwei Bildern extrahiert wurden, gibt es meistens viel Noise. RANAC kann mit dem gut umgehen.
Wenn die Fundamental Matrix bekannt ist, kann mit hilfe der Kallibrierungsdaten der Kamera die Essential-Matrix berechnet werden ( ).
).
Danach kann die Essential-Matrix als E=R * S decomposed werden, wobei R eine Rotations-Matrix ist und S die Position enthaltet.
Folgendes ist die Definition von S.
