Processes
Each program can have many processes. These run in user mode, while the kernel itself runs in kernel mode.
Creation
When the parent-process requests the creation of a new child processes, the Linux kernel will create a new child process with an exact copy of parent's memory map.
This can be either be done with:
- Distinct Address Space The memory for the child is a copy in a different memory area
- Copy-on-Write When spawning the child, nothing is copied. As long as the child only reads, nothing is copied, but as soon as the child tries to write, then the required memory is copied.
Termination
A process can terminate in multiple ways:
- The process is done and exists voluntary
- An error occurred in the process (like a resource doesn't exist) and it exists voluntary
- An error occurred in the process (like a segmentation fault, or divide by zero) and exists involuntary
- The process was murdered/killed by the OS
Process State
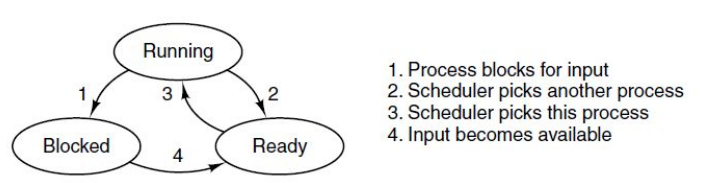
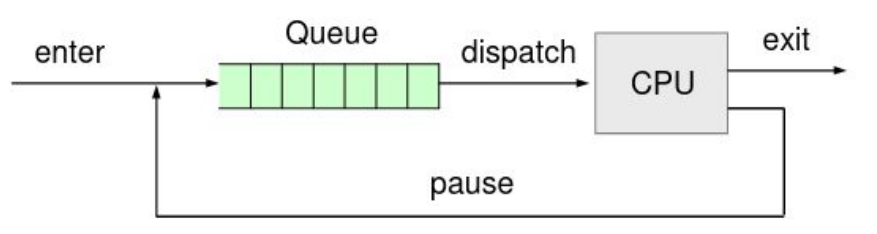
If the process is ready, then it is put in to the queue for the kernel to be scheduled. Once the kernel picks the process, the state of the process is running. If the process needs access to resources (like a busy hard drive), the state is set to blocked. In this state, the process is not ran and not dispatched.
The process' state might change because:
- The CPU allocated time expired
- An interrupt happend and the CPU needs to handle it
- A page fault happen
- The process requests a system call and the kernel takes over
User Mode vs System Mode
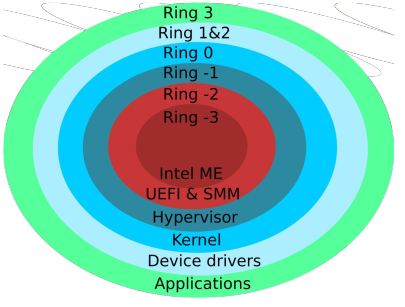
All applications run in user mode, where there have access to a limited set of instructions. When a process wants to do something, they use a system call to request this from the kernel.
The kernel runs in system mode (or kernel mode), where it has access to the complete set of instructions.
Mode vs Context Switch
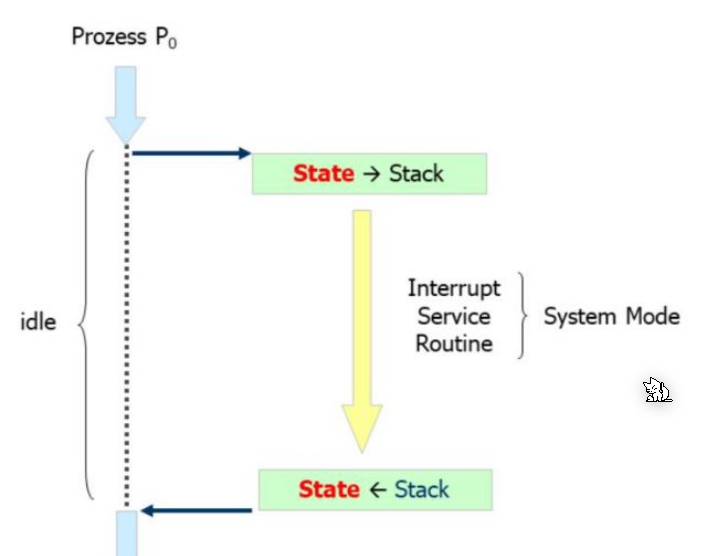
The process might call a system call or an hardware interrupt happend, the kernel needs to switch to kernel mode, execute something, an then the context of \(P_0\) is restored.
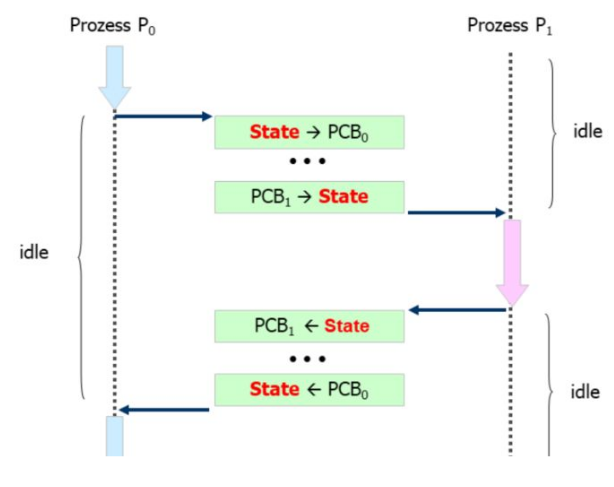
On a multi-processor, the scheduler tries to only give out time slices to different processes. If the slice expires, first a mode switch happens. Afterwards, a context switch happens, where the kernel switches the environment to the other process. This needs to be done in kernel mode, which is why the mode switch is necessary.
After the context switch, the mode is reverted to user mode and the new process receives control over the CPU.
Process Control Blocks and Process Table

The kernel maintains a linked list of process control blocks, named for process tables, for all processes.
Threads vs Processes
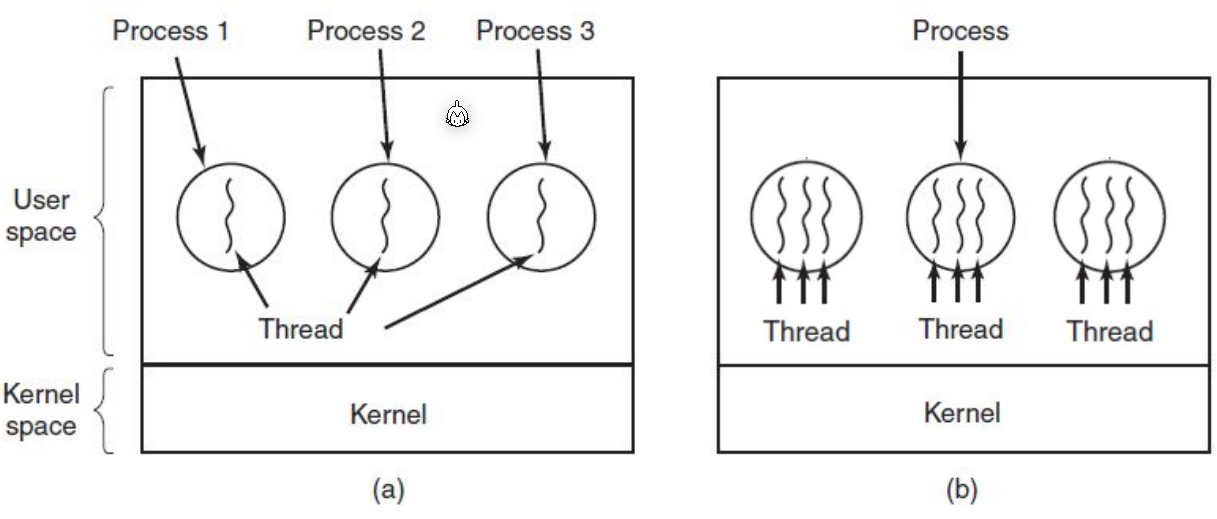
The difference between processes and threads, is that threads share the same context, while processes have different contexts, which needs to be switched.
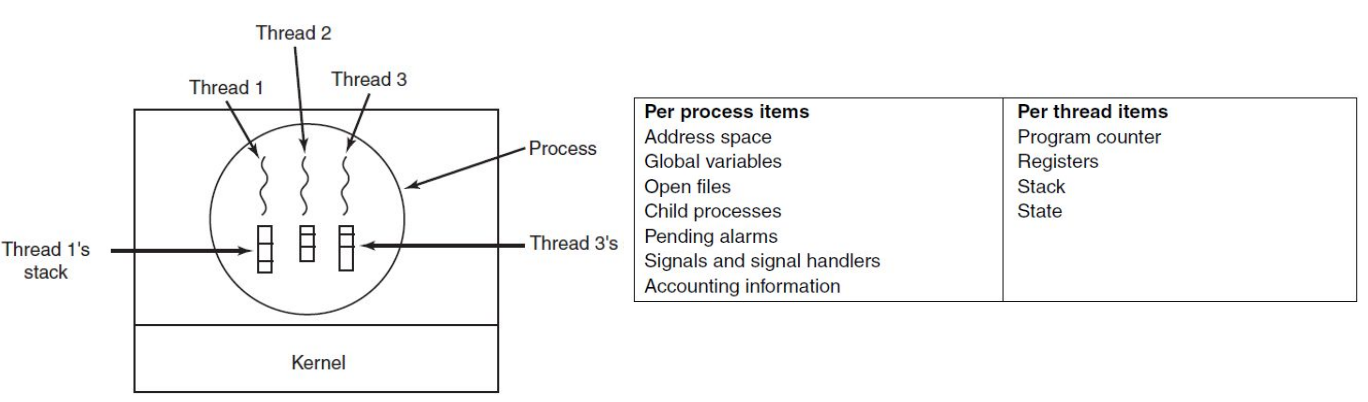
Each thread has its own program counter, registers and stack, but share the other process resources. Because of this, threads are a lot lighter than process, as creating threads and switching between them is a lot cheaper.
Threads can be managed by the process itself or the kernel. However, if the threads are managed by the process and a system call in invoked then the process will be blocked and suspended. This negates the usefulness of threads.
POSIX Threads
The POSIX Thread library implements threads managed by the process.
- Advantage
- The software is portable
- Less overhead for thread management
- No mode switching
- Disadvantage
- All threads can only run on one execution unit
- System call release the rest of the remaining time slice
Kernel Supported Threads
With kernel supported threads, the kernel manages threads as if they were processes (The kernel doesn't actually has a concept of threads) with shared resources. Which resources are actually shared is configurable.
- Advantages:
- IO blocking is no issue
- Can run on multiple execution unites simultaneously
- Disatvantages:
- The kernel has more overhead
- The creation and removal is slower
- The kernel needs to mode switch to switch between threads
- The software is less portable
Kernel Threads
A kernel thread runs in system mode and is part of the kernel itself. This thread also has an entry in the process table, but is flagged as a "Kernel Thread".
Kernel thread is scheduled and dispatched by the scheduler, does not need a mode switch, and cannot be interrupted.
Kernel threads are used with a thread pool of the kernel. This pool is dynamically managed by the kthreadd kernel thread.
Top
Scheduling
The schedulers needs to schedules on different events:
- When a new process has been created
- When a process exists
- When a process is blocked on I/O
- Regularly on a timer
There are different types of schedulers:
- A uni-process There is no need for a scheduler as there is only one task
- Multi-processing
- Multi-tasking
There are different scheduling types:
-
First-in-First-out The first task is executed to completed (without preemption). This can lead to infinite loops. One possible objective could be to favour the earlier
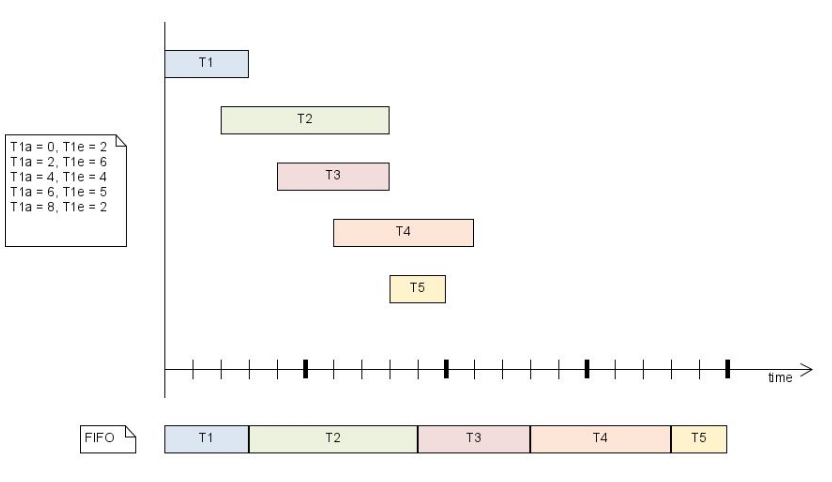
-
Round-Robin Each tasks gets a slice of time and is then preemptively stopped. The objective is fairness
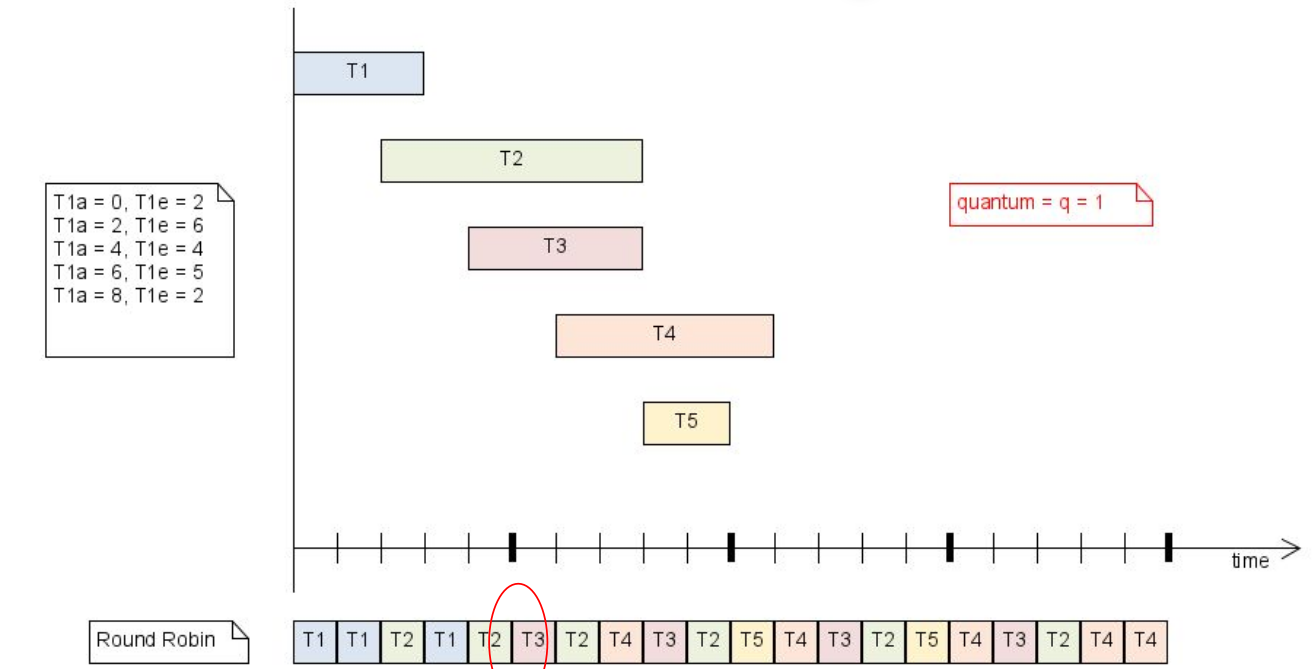 One edge case is, when a task is added, if the new task is run or if the previous order is continued. The implemention needs to decide whether the scheduler favours newly arriving tasks or older tasks
One edge case is, when a task is added, if the new task is run or if the previous order is continued. The implemention needs to decide whether the scheduler favours newly arriving tasks or older tasks -
Multi-Level
If tasks have priorities, tasks are put in the queue for the specific priority. The scheduler will first run all the blue tasks, then the green tasks, and then the yellow tasks. However, this can lead to low priority tasks starving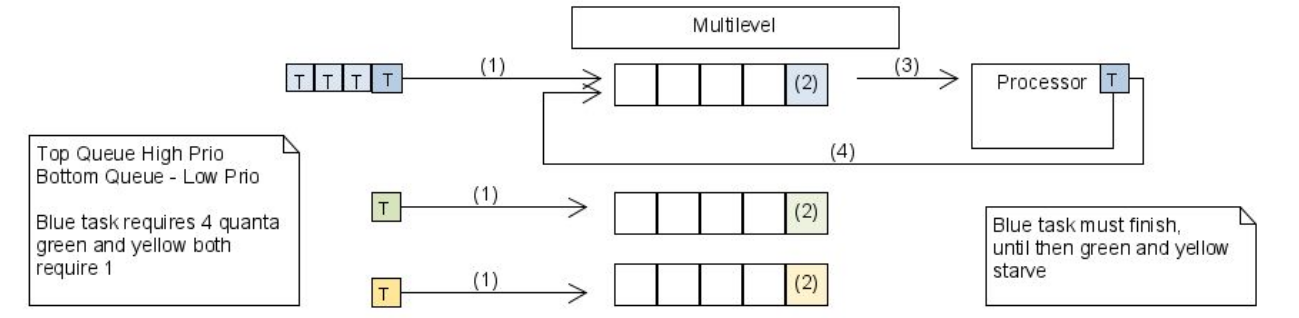
-
Heuristic

-
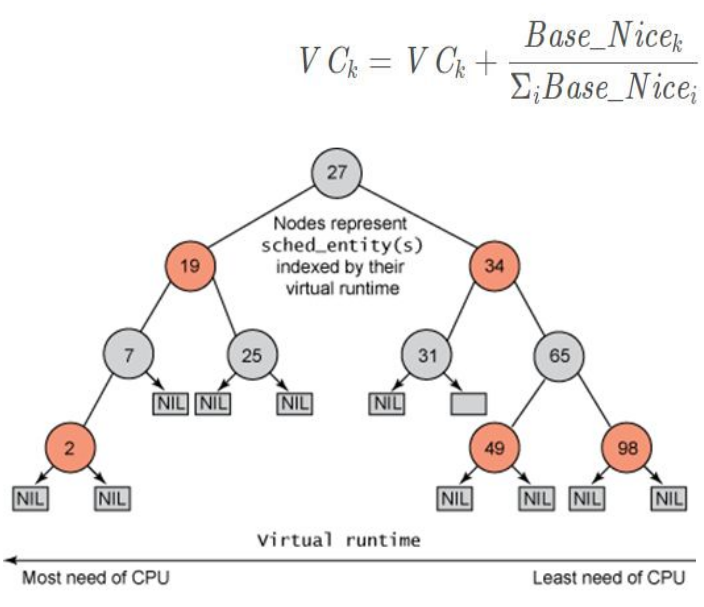
Fair Share Scheduling
A virtual clock is calculate running for each task. The scheduler ensures that on average the run-time given to each task is equal
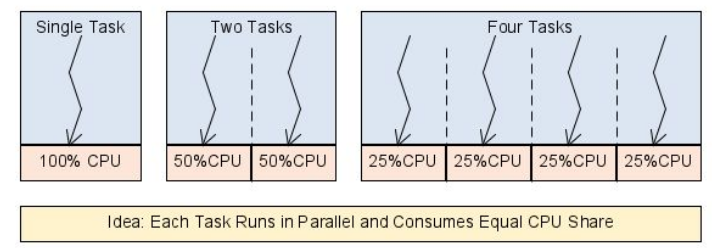
This scheduler is used in linux and ensures that all process received the same amount of processing time.
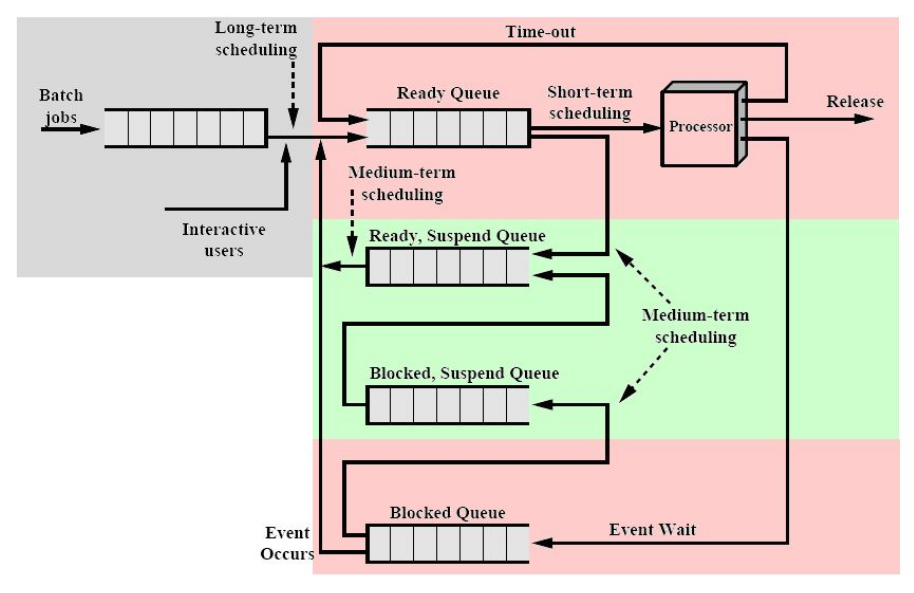
If a process is requesting a resource (like a file for the hard drive), the os will put the process into the Blocked Queue, where until the requested resource is available, it will stay.
Policy
Different schedulers have different policies to reach their objective.
All schedulers have:
- Fairness
- Policy enforcement
- Balance
Batch systems usually have the following:
- TODO
Interactive systems usually have the following:
- TODO
Real-time systems usually have the following:
- TODO
Metrics
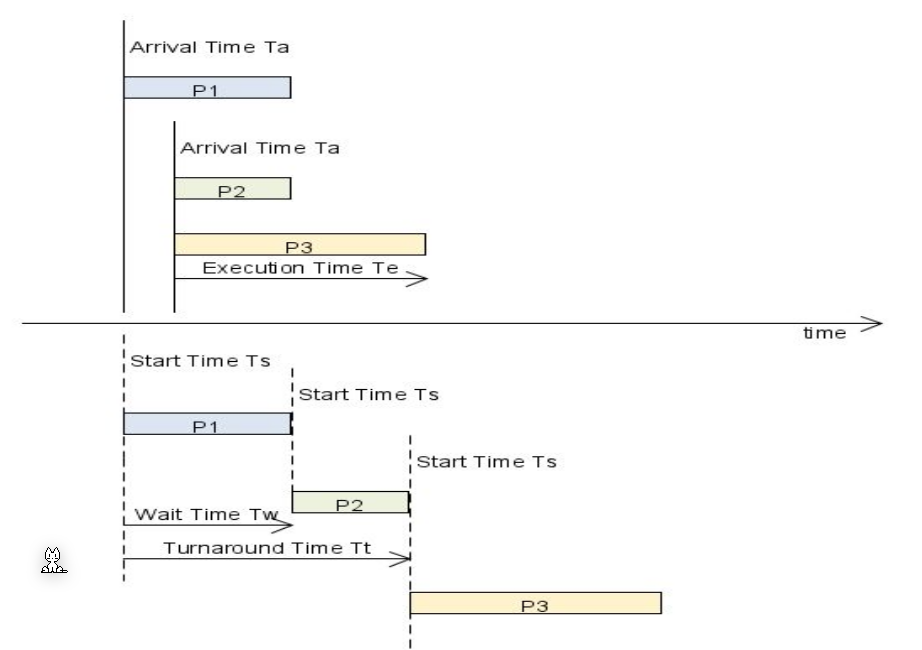
Tasks have an arrival time, a start time and an execution time. The turnaround time is equal to wait time + execution time.
Real-Time Schedulers
A real-time schedulers can ensure that deadlines are met. There is a distinguished between hard deadline, which have to absolutely be met, and soft deadline, where there is some wiggle room.
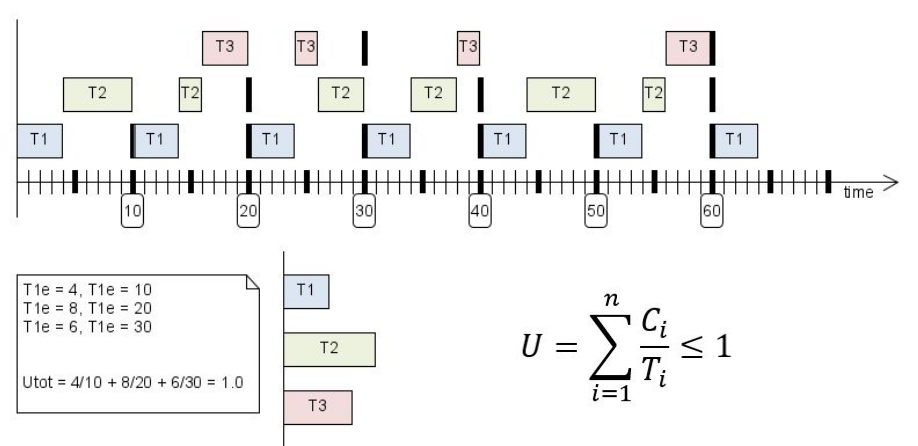
Rate-Monotonic
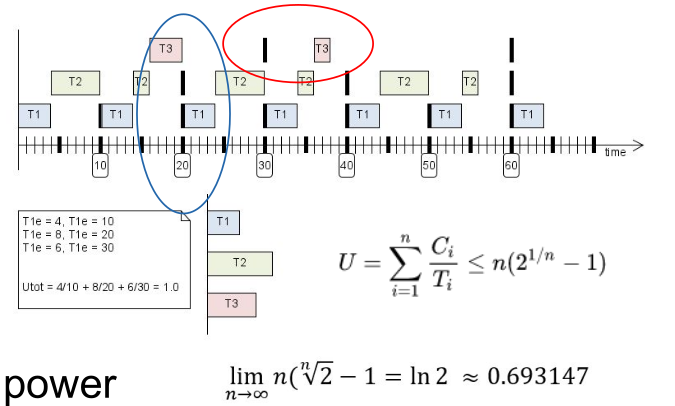
A rate monotonic scheduler gives the highest priority to the task with the highest repetition rate.
In the formula, \(C_i\) is the run time of a task, \(T_i\) is the period after which it should scheduled again and \(U\) is the utilisation. (The first column in the note is \(C_i\) instead of \(T_{ie}\))
If the utilisation is above \(69%\) the scheduler can meet all deadlines. Above this, some tasks might miss their deadlines. This means that this is rather expensive, as \(~30\%\) is unused.
Earliest Deadline First
The task with the earliest deadline is dealt first
Linux
Linux maintains a single execution queue and can use different tasks with different schedulers.
The priority is:
- Real-Time Schedulers
- Normal Schedulers
SCHED_OTHERSCHED_BATCHSCHED_IDLE
Multicore System
The scheduler on a multicore system wants to run a process on the same core each time for caching reasons. Moving processes between.
With the /proc/sys/kernel/rt_runtime parameter, one can tell the kernel, how much time it should spend on real time tasks and non-real-time tasks.
Nice
The nice value ranges between -20 and 19 and tells the scheduler how willing a task is to surrender cpu time to other tasks. This, however, isn't a hard priority and the scheduler can override the nice value at any time. It is only a suggestion.
The nice value does not affect the real time scheduler.

SCHED_DEADLINE (Real-Time)
SCHED_DEADLINE has the highest priority and tasks executed with this schedulers are not allowed to fork. Tasks can yield the remaining time with a syscall.
SCHED_FIFO (Real Time)
There is a queue for each priority (conceptually 198 queues). If a task enters a higher priority queue than the current running task, then the running task is preempted.
Tasks with SCHED_FIFO will run to completion, unless
- preempted by a higher priorty real-time thread
- blocked by I/O call
- yields the cpu time with
sched_yield
SCHED_RR
The round-robin scheduler has multiple queues for each priority.
SCHED_OTHER (Fair Share Scheduling)
The complete fair scheduler
SCHED_BATCH
Can be used for batch processes. These are processes that do some steps without interaction (e.g end of the month salary calculations).
SCHED_IDLE
This scheduler runs tasks if no other productive tasks are running.